Januari 10, 2004
| Document Information | |
|---|---|
| Version | 0.25 |
This document describes the technical specifications for the Gnucomo project. It will describe the functionality achieved, design specifications and choices made. The document will be the manifest for the developers to work in the same direction and not run into unneeded disappointments.
| Version | Author | Date | Remarks |
|---|---|---|---|
| 0.l | Brenno de Winter | Jul 11, 2002 | Initial version |
| 0.11 | Arjen Baart | Jul 12, 2002 | Additional guidelines and dataflow diagram. |
| 0.12 | Brenno de Winter | Jul 15, 2002 | Database design added |
| 0.13 | Arjen Baart | Jul 16, 2002 | Entity-relationship model added. |
| 0.14 | Brenno de Winter | Jul 17, 2002 | Based on feedback. Small changes to the datamodel and finishing touches in lay-out of the tables. Added some examples. |
| 0.15 | Brenno de Winter, Arjen Baart | Jul 21, 2002 | Additional feedback processed, indexes added, ERD added and SQL-script created. |
| 0.16 | Brenno de Winter | Aug 7, 2002 | Communication handling added. |
| 0.17 | Brenno de Winter | Aug 11, 2002 |
* Description of the client-side for communications. * Several updates to the database descriptions, drawings added. * More work on the installation chapter. * Created an extra field to the unprocessed_log table and added a between the table service and unprocessed_log. |
| 0.18 | Brenno de Winter, Peter Roozemaal | Aug 15, 2002 |
* Review done by Peter Roozemaal: adjusted intro and several clarifications made * Arjen Baart: Adjustments to database drawings * New installation recommendations |
| 0.19 | Arjen Baart | Aug 27, 2002 | Conversion to XMLDoc |
| 0.20 | Arjen Baart | Oct 20, 2002 | Minor layout improvements |
| 0.21 | Arjen Baart | Nov 07, 2002 | Installation instructions added. Combined chapters 4 through 7 into one chapter (4). |
| 0.22 | Arjen Baart | Nov 15, 2002 | Added parameters of monitored objects. |
| 0.23 | Brenno de Winter | Dec 6, 2002 | Added new elements to the database |
| 0.24 | Brenno de Winter | Dec 12, 2002 | Updates to the database to reflect the most recent changes. |
| 0.25 | Arjen Baart | Jan 10, 2004 | Added a list of related projects and introduced the concept of dynamic parameters. |
The number of log-files in a system and the tools in general do not make monitoring a system simple. Quite often there is so much information that attention for logfiles seems to fade away. For that reason monitoring routers and clients is often not an option. Instead of timely detection of problems, logs more often are used to find out what went wrong. When a system is under attack early signals can often easily be detected1 and preventive measures could have been taken if the time was only available.
The Gnucomo project is meant to make pro-active monitoring of computers and devices easier. It will contain a set of applications that will retrieve all types of monitoring information from devices and place it into a database. Devices can be server computers, desktop computers, PBX'es or other systems. By running checks the manual process of watching log files can be reduced. Also an intelligent script can see things that a human being will easy overlook. Gnucomo won't relieve an administrator of all manual work on log-files, but will increase the changes on actual monitoring.
With all this data being available at one central location the gnucomo-server acts as some kind of black box for computer systems. If something does happen the evidence will be available at a remote location available for exploration2. Forensics will be made easier. Also the collected data is available from multiple locations make it easier to found more about an attack. The change that you overlook things will be reduced.
Based on the entered data all sorts of analysis will be performed to discover abnormalities a normal maintenance tool or IDS wouldn't be looking at. An example could be a website in Dutch that suddenly obtains a lot of attention from Greek visitors (based on the location of their IP3). These abnormalities will be presented as user-friendly as possible to increase awareness of the state of the system. By doing that the system can also be used for more complex analysis. One than can look at long-term trends like hacking attempts that take place, new exploits that are tried all of a sudden or signs of distributed attacks or a certain pattern of attempts4.
Also extra data will be gathered where ever possible to save time to the administrator. If IP address attract attention of gnucomo the next logical step would be to use tools like dig, whois and visiting arin-related websites. This data will automatically be collected in an early stage and stored in the database.
The results will be gathered in a warning system. Those warnings will be presented to the administrative person who is responsible for that particular machine or network. Having multiple systems in the system can add to the intelligence that can be gathered. The interface will be web-based and aimed at user-friendliness.
Since multiple systems can enter data into the Gnucomo database more intelligent hardware and security detection can be done. When things do go wrong Gnucomo contains as much information as possible to figure out what happened and assist in the forensics. Since research on the signals afterwards is broader more attention will be given as much data as possible and do less filtering.
With the data in the database also policies can be checked automatically retro-actively so that the security leaves some room to stretch some rules. This may sound not logic, because one of the main functions of security is to enforce rules. But some rules are made with the different meanings. For instance: a rule may be that private browsing isn't allowed. The background of such a rule might be to try and reduce the amount of data traffic (too many people downloading mp3's, or people not getting to work anymore). By monitoring that specific fact (bandwidth spent on non-business related Internet use) it's possible to be relaxed on that rule and enable many good-willing users reading his/hers daily newspaper.
The scope of the project is clearly limited to monitoring and not to offer automated maintenance or web-based maintenance. There are other projects currently being able to provide that functionality. We will focus on intelligence and user-friendliness of representation of facts presented. A warning should trigger an administrator to get up and do something using the tools he or she values the most.
Also we are not aiming to replace great tools like SNORT as a real-time IDS. These tools can do thing, that in the beginning won't be a part of gnucomo out of performance reasons. Also there is no need to duplicate what they already did. If that energy is placed in intelligent we're very complimentary. Gnucomo can however be a reality check on an existing NIDS (Network Intrusion Detection System). For instance if warnings keep coming it may be time to rethink the rules that have been set.
This evolves to the following list of functions gnucomo can provide:
In order to get the project running we have to make some decisions before we can start. Of course are the decisions always open for review, but initially our main aim is to get a system running. This doesn't mean that we allow a lesser architecture, but more that we create an environment that will lead to results.
The following decisions apply to the system in general:
The overall systems aims to make maintenance data better accessible and by doing that lowering the barrier to be on alert for intrusions, system failure and other misery that can happen to computer systems. Also more systems can be monitored and even focus can be placed on desktop computers, something that nowadays rarely happens. Since the solution is only aimed at monitoring (with some responses possible) other people can watch their system(s) without being Administrator6.
The main system will know to sides:
The project has been setup as a two sided system in order to be able to guard many computers at the same time. However it may be obvious that both sides of the application can very well be installed on a single system.
To monitor a system, Gnucomo uses two kinds of input: event and parameters. Events occur on a system while it is running and reflect the transient behaviour of the system. Parameters reflect the current state of the system. The most obvious way to gather events from a monitored system is to read the system log files. Examples of events are IP packets that are rejected by the firewall or clients that access the http daemon. Parameters are obtained for example by reading configuration files or kernel data structures. Examples of parameters are the size and free space of a filesystem or the users that are listed in the password file. Both kinds of input are obtained actively or passively, i.e. by installing probe agents in the system which regularly aquire the system's parameters or passively by sending the output of programs to the Gnucomo server.
When signals7 arrive they will be stored in a file. When this file is delivered to a certain directory a daemon will detect this and start the transfer of the file. The file will be transferred to the central application or the client. This transfer will be triggered immediately after a process has finished or with a certain time-interval when it concerns a logbook. All output will be placed in a directory where the daemon detects it and ensures the transport. For transport currently only two mechanisms will be supported:
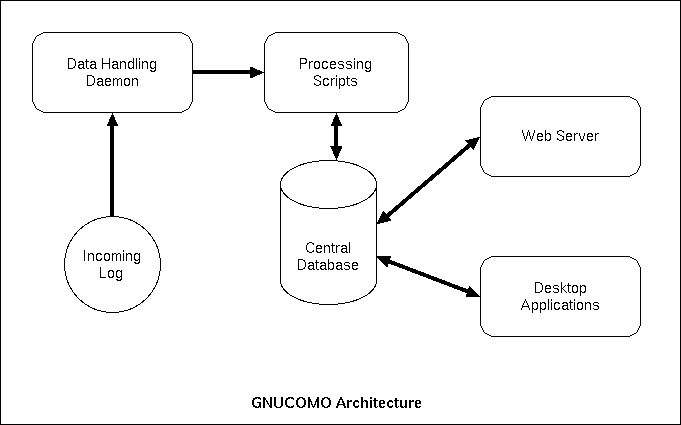
Illustration 1 Basic overview of the processes on the server.
On one machine signals from the network will come in. These signals can be logfiles, result files from applications, remarks entered by the administrator or whatever. Data delivery takes place into a certain directory. A daemon detects that data has come in and will enter it into the database. Once in the database stored procedures and triggers will recognize certain behavior and generate alerts. The user responsible for the server will be confronted with the alerts and can mark them, add comments to it or ignore them. Also it will be possible to do intelligent analysis on not so logical relations per computer or across computers8. Such scripts make detection possible, that is too time consuming to do during processing of the data.The data processing has four tasks:
Gnucomo maintains the operational parameters of a monitored system for a number of reasons. The most important reason is to create notifications when somthing about a parameter changes while the parameter is not supposed to change. Such a change may be intended by the system administrator, e.g. when a package is upgraded, or there may be something wrong. In any case, you will want to know about a change in your system when it happens. Furthermore, a change history of a parameter's values will come in handy when you want to look back in time and figure out what happened in the past. Another usefull application of parameters concerns the maintenance of a large number of similar systems. When the parameters of each system are reported regularly to Gnucomo, deviations from the 'standard' system configuration can be easily spotted.
Some properties of parameters are supposed to change regularly. A changed value of such a property will of course not lead to any notification. On the other hand, the change history of these parameters may provide interesting information about the monitored system. This leads to the distiction between static and dynamic properties of parameters. The difference between dynamic and static properties manifests itself mainly in the change history of the parameter's property. Dynamic properties typically have a change record once a day or even a couple of times a day. Change records for static properties are usually months apart. If all properties of a parameter are dynamic, the parameter as a whole is regarded as a dynamic parameter. One of the properties of a dynamic parameter is that it does not need to exist all the time, i.e. it does not have to be listed in every report.
The state of parameters is scanned or probed regularly on a client system and reported to the Gnucomo server. These reports can be created in a variety of ways. For example, filesystems are reported with 'df', installled packages with 'rpm -qa', users by reading /etc/passwd, etc. Many other probing methods may be implemented. Each report from a probe holds the current value of several parameters. Gnucomo will check each property of these parameters against the stored knwon value. If the property's value changed, the actual value in the database is updated and a record is added to the change history of the parameter. When a parameter is listed in the report but that parameter is not in the database or the other way around: a parameter is in the database and is not in the report, this constitutes a notable change in the system.
Whenever the state of the system's parameters changes, Gnucomo may create a notification. Notifications are created when one of the following changes happens:
The web interface will used to interact with the user. The interface should be intuitive and easy to understand. More important warnings should directly draw attention. The user must be able to perform settings so that warnings can be rated differently than the original settings.
The interface will do the following things:
Each notification has a certain priority that requires a different handling of the issue. How each priority will be dealt with is something that can be set per server. The priority mechanism is a simple system of five categories (can be more or less).
The main dataflow will be as follows.

One of the main tasks is getting all the messages to the database. Ultimately gnucomo will support multiple ways of receiving the data. Basically anything goes, but two mechanisms will be supported in the project to begin with:
<TO BE DESCRIBED>
Files will be dealt with as if gnucomo were a user (actually there will
be a user gnucomo). The files will be placed in the /home/gnucomo/ directory.
Only /home/gnucomo/incoming/dropbox/ can be used to save data in
from external systems. All other directories are only available for the user gnucomo.
The filename will represent the data that is received. The details are seperated with
underscores. When data is sent by e-mail the filename will be written in the first
line of the e-mail. A typical filename looks like this:
3_messages_20020807235208_1.asc
the logic behind this is following:
urgency_typeofmessage_timestamp_objectid.typeoffile.
|
Part of filename |
Explanation |
|---|---|
|
Urgency |
This indicates the urgency of the file. The lower the number the higher it will rank when an overview is given. Standard files are ranked value 3. The ranking works as follows: * 1 Urgent flash message. Something urgent needs to be reported. This is only used for emergencies like serious alarms. * 2 Rapid delivery. An important message has to get through that is more important than normal delivery, but is not top priority like an emergency. * 3 Normal. This is used in most case for normal messages. * 4 Low priority. This is data would be useful to place into the system as nice to have. |
|
TypeOfMessage |
This is an indicator what type of data is delivered to gnucomo. There are several categories: * cron. This data comes from the /var/log/cron-log (unix). * httpaccess. This data comes from the normal http-log (Apache). * httperror. This data comes from the http_error-log (Apache). * maillog. This data comes from the /var/log/maillog (unix). * messages. The data delivered here comes from the /var/log/messages file (unix) * text. This file contains a message in plaintext generated by a gnucomo-client and can be anything. It will be dealt with as plaintext. |
|
Timestamp |
The timestamp is made in war-log (YYYYMMDDHHMMSS) format. The timestamp is generated on the client in GMT (to discover discrepancies in timing). |
|
Objectid |
The objectid is the id that is used within the central gnucomo system to recognize the client. Based on this entry the database can link the data to the correct object. Also gpg can obtain the correct e-mail address (by running a query in the database) for verification of the signature of the crypted message. |
|
TypeOfFile |
Indicates the file type: * asc. Plaintext ASCII * gpg. gpg-crypted data. * und. Undertermined data. When files come in by e-mail it is not 100% sure if they are crypted or not. These data has first to be analyzed before it is moved to the correct queue. |
For incoming messages there will be separate directories
(/home/gnucomo/incoming/)for:
/home/gnucomo/incoming/dropbox/
/home/gnucomo/incoming/crypted/
/home/gnucomo/incoming/cryptfail/
/home/gnucomo/incoming/inbox/
/home/gnucomo/incoming/processed/
/dev/null.
The used directory is: /home/gnucomo/archive/
For outgoing messages the directory /home/gnucomo/outgoing will
be used. This directory knows a couple of sub directories:
/home/gnucomo/outgoing/dropbox/
/home/gnucomo/outgoing/outbox/
/home/gnucomo/outgoing/processed/
/dev/null.
The used directory is: /home/gnucomo/archive/
The total directory-structure looks like this:
/home/gnucomo/
/home/gnucomo/archive
/home/gnucomo/incoming
/home/gnucomo/incoming/crypted
/home/gnucomo/incoming/cryptfail
/home/gnucomo/incoming/dropbox
/home/gnucomo/incoming/inbox
/home/gnucomo/incoming/processed
/home/gnucomo/outgoing
/home/gnucomo/outgoing/dropbox
/home/gnucomo/outgoing/outbox
/home/gnucomo/outgoing/processed
On the client-side the files that need to be transmitted will be placed in a directory system as well. In the future this system may not be in use at all devices (routers, certain MS Windows-machine, IP Telephones, etc.). For those systems a different mechanism will become be described here. Initially we focus on Linux systems that will enter data into the database.
The filename convention will be totally identical to the filename convention on the server, since this the same mechanism.
To facilitate gnucomo client and server on one and the same machine the gnucomo-client should have a different default user. For this purpose the user gcm_client will be created.
For incoming messages there will be separate directories
(/home/gnucomo/incoming/)for:
/home/gcm_client/incoming/dropbox/
/home/gcm_client/incoming/crypted/
/home/gcm_client/incoming/cryptfail/
/home/gcm_client/incoming/inbox/
/home/gcm_client/incoming/processed/
For outgoing messages the directory /home/gcm_client/outgoing will be used.
This directory knows a couple of sub directories:
/home/gcm_client/outgoing/dropbox/
/home/gcm_client/outgoing/outbox/
/home/gcm_client/outgoing/processed/
The total directory-structure looks like this:
/home/gcm_client/
/home/gcm_client/archive
/home/gcm_client /incoming
/home/gcm_client/incoming/crypted
/home/gcm_client/incoming/cryptfail
/home/gcm_client/incoming/dropbox
/home/gcm_client/incoming/inbox
/home/gcm_client/incoming/processed
/home/gcm_client/outgoing
/home/gcm_client/outgoing/dropbox
/home/gcm_client/outgoing/outbox
/home/gcm_client/outgoing/processed
The files in the /home/gnucomo/incoming/inbox/ should be stored in the database. For this purpose there is a table unprocessed_log. The data of the filename as well as the content of the file need to be placed in one record.
There are some fields that have to be addressed immediately:
The daemon application that delivers the data is called gcm-input. It performs the following steps with no extra functionality:
Detect if a file is available.
Write the data in the database.
To write the data in the database a database user gcm_input exists. This user has only the right to enter data into the database. There are no deletion, update or select-permissions.
The database is the heart of the system. It will contain all event-data of multiple computers. The intelligence that can be performed on the database will be placed there. To do this as integratedly as possible stored procedures and triggers will be used. To begin with we have selected checks to be performed that will be expanded throughout time.
Since the gnucomo database and files contain sensitive data security measures have to be in place. Several database users will exist that have limited rights to perform a certain task ensuring some protection against unauthorized access. However these mechanisms on it's own will work fine, bad maintenance may still screw-up good security. Good database maintenance is needed. For the gnucomo the protection of the valid authentic nature of the data in the database has our highest priority.
A table-name in this chapter is written in cursive writing.
The database will be built according the following conventions:
In the design we anticipate to deliver an as best as possible database performance. That means that data that needs to be entered occasionally can be heavily indexed to increase performance. However data that is mainly stored will only be indexed marginally to have the best possible performance on data entry. If during one of the checks on data-entry a notification is made, the information related to that notification will be indexed very well to increase retrieval performance. What we will try to avoid is that the user interface will cause full table scan and affect the performance of the overall system dramatically. One of the techniques to increase performance on display is to work with views. So where it is feasible we will use them.
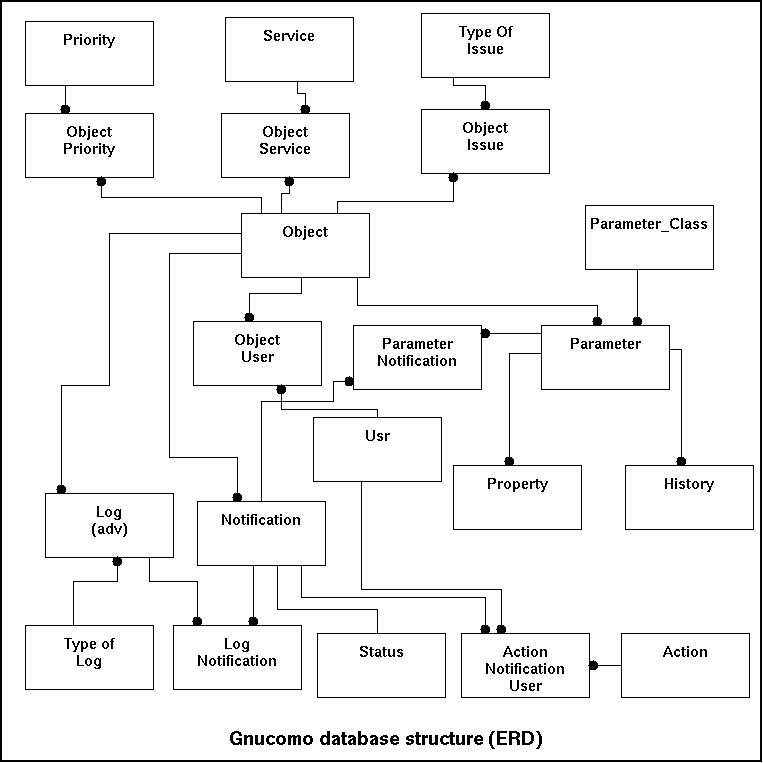
The following model pictures the database as described in the remainder of this chapter.
In general the database must also be maintained well. So daily maintenance scripts should keep the performance good10.
In this part of the chapter the tables will be explained and then described with all important elements. Per table a sub-chapter will be created. Each table will have a table design, indexes, relationships and the required data (for those tables where the data itself is relevant in the design or sample data (for those cases where no set data is needed). For the relationships beside a description the subset of the total schema has been incorporated in the document so that it is more clear what exactly is meant. Due to the complex nature of the design those drawings sometimes will seem funny.
For the fieldtypes the types of PostgreSQL will be used. These values can be found in Chapter 3 of the PostgreSQL User Manual (http://www.postgresql.org).
For indexes primary keys are always unique and called primary key in the name. Since unique indexes within PostgreSQL only work on B-Tree indexes (which is default) we will use B-Tree for all indexes. In cases where an exception is made the used type of index will be indicated in the characteristics. A footnote will explain why a different type of index has been selected.
This table stores the actions that are recognized by the system. Whenever a situation in the database has been raised (through the table notification) one expects steps to be taken to resolve these issues. All these steps are stored in this table. Each step beginning with detection until a case is closed can be traced back through this table. This will support the accountability (who is responsible for which action) and non-repudiation (being able to trace what exactly happened to each notification). In the table action all recognized actions that can be taken are stored. Several of the taken actions will lead to change in statuscode. When this is the case either the server-side of the interfaces or the gcm_daemon will perform this task. This doesn't apply to all actions though.11. Actions take place through background processes and the interface. Each action known by the system will be delivered by the software. This table mainly is used for retrieval so indexing will be done as much as possible.
The table below describes the fields:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| actionid | Bigserial | 8 | Autonumber bigint (eight bit). Unique identifyer to refer to when this action is taken. |
| actionname | Text | Short descriptive name for the type of action. | |
| statuscode | Varchar | 3 | New status that will be given to a notification when this action takes place. If the action occurs the status in the notification can change because of this. The statuscode will indicate what the new status has to be. If this field is left empty no change to the status will occur. |
| description | Text | A longer description (without limit) on the action. |
Indices for this table are:
| Indexname | Field | Characteristics |
|---|---|---|
| act_pk | actionID | Primary key |
| act_actionname | actionname | Unique |
| act_statuscode | statuscode |
Relationships with other tables:
| Fieldname | Remote Table | Remarks |
|---|---|---|
| actionid | action_notification_user | Each action that takes placed will be stored. The Actionid will bring classification to the individual records (that reflect what it means if the action-occurred). This relationship has to be enforced. |
In the model this looks like this:
The data in this table is standard for the system and part of the design. The user cannot change this or add value to it.
| Actionid | Actionname | Statuscode | Description |
|---|---|---|---|
| 1 | Entry in the system | NEW | This indicates that a notification is entered into the system. The status is a NEW. |
| 2 | Displayed to user | OPN | The notification has been displayed to the user. It is not guaranteed that the user has read the notification, but he/she should be aware of it. The status will now be changed to OPEN if the current status is NEW. |
| 3 | Remarks added | PEN | Remarks have been added to the notification. The status has now been changed to PENDING. |
| 4 | Priority changed manually | PEN | The priority of the notification has been changed by the user. The new status is now PENDING. |
| 5 | Priority changed automatically | PEN | The priority of the notification has been changed by the system. If the status is not OPEN or NEW the new status is become PENDING. |
| 6 | Action taken | PEN | A action has been taken. The status is now PENDING. |
| 7 | Assignment to user | PEN | A notification has been explicitly assigned to another user. The status is now PENDING. |
| 8 | More information or research needed. | INV | The notification is relevant and will be handled, however more information or research will be needed. The status is UNDER INVESTIGATION. |
| 9 | Make output reference. | REF | Automated output from an object has been sent to gnucomo. The input has been identified as a valid reference for future. Status is now REFERENCE12. |
| 10 | Job output no longer reference. | CLS | By making a newer job output reference this output has been obsoleted. Since once it was a reference the notification can be closed. The new status for the notification is now CLOSED. |
| 11 | Action taken please verify. | VRF | An action has been taken and things should have been resolved. Before the notification can be closed a verification has to be done. New status is now VERIFY. |
| 12 | Action not accepted. | PEN | A check has been done and the results were not good. New verification is needed. New status is now PENDING. |
| 13 | Action verified | CLS | The verification for the action has been done and the action is approved. The new status is now CLOSED. |
| 14 | E-mail sent | OPN13 | An e-mail has been sent. |
| 15 | SMS sent | OPN14 | A SMS has been sent. |
| 16 | Fax sent | OPN15 | A fax has been sent. |
| 17 | Log-entries shown | XXXX | The log entries have been shown. No changes to the status made. |
| 18 | Notification closed | CLS | Notification has been closed. |
| 19 | Notification reopened | OPN | Notification has been re-opened |
This table stores each actual action taken. Where the action basically stores the type of actions that can be taken, this table says 'at this point in time for this notification this action was taken'. Using this table it is traceable who did what at which moment in time. The table is very important for later use if something goes wrong, but is also relevant for the interface. All steps of a in the process of a notification can be traced using this table. There will be a lot of entries here, but retrieval is more crucial for performance than data entry. So indexing on logic fields is very relevant. Processing might be slower, but that's worth the price.
The table below describes the fields:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| actionstepid | Bigserial | 8 | Autonumber bigint (eight bit). A unique identifyer to indicate each step in the process. |
| actionid | Bigint | 8 | Reference to the action that is being registered here. This field refers to the actual action taken. |
| username | Text | The username of the user that is involved in the action. This field refers to the table usr | |
| notificationid | Bigint | 8 | Reference to the notification. This will link the action to the notification. |
| timestamp | Timestamp | The time when the action has been entered into the system. This is the time without the timezone16. This will be automatically added when the record is added into the database. | |
| statuscode | Varchar | 3 | The status of the Notification AFTER this action has been taken. |
| remarks | Text | Remarks entered by the user if it concerns a manual action or the text of automatically generated warnings. |
The table is indexed on the following fields:
| Indexname | Field | Characteristics |
|---|---|---|
| anu_pk (action_user_actionstepid_key) | actionstepid | Primary key |
| anu_actionid | actionid | |
| anu_username | username | |
| anu_notificationid | notificationid | |
| anu_timestamp | timestamp | |
| anu_statuscode | statuscode |
Relationships with other tables:
| Fieldname | Remote Table | Remarks |
|---|---|---|
| actionid | action | Indicates the action that has been taken. The relationship has to be enforced. |
| notificationid | notification | Each action that takes place is registered in this table. By using the notification the relevant notification. The relationship has to be enforced. |
| username | user | Each step in the process has to be related to the user. If the system itself generates an action the user will be gnucomo17. |
In the model this looks like this:
Since no data is delivered automatically a couple of sample records are shown here.
| Actionstepid | Actionid | Notificationid | Username | Timestamp | Status | Remarks |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | Gnucomo | 2002-07-14 16:14:09 | NEW | Gnucomo detected a portscan |
| 2 | 5 | 1 | Gnucomo | 2002-07-14 16:14:09 | NEW | Priority set to: 3 |
| 3 | 5 | 1 | Gnucomo | 2002-07-14 16:14:09 | OPN |
Automatic e-mail to user: brenno@dewinter.com: Gnucomo detected a portscan on system gnucomo.dewinter.com |
| 4 | 2 | 1 | Brenno | 2002-07-14 16:18:09 | OPN | Notification shown through webinterface. |
| 5 | 17 | 1 | Brenno | 2002-07-14 16:18:12 | PEN | |
| 6 | 4 | 1 | Brenno | 2002-07-14 16:20:37 | PEN | Priority set to: 1 |
| 7 | 3 | 1 | Brenno | 2002-07-1416:21:58 | PEN | After reviewing the logs I see a portscan. On very specific ports. More analysis needed. |
| 8 | 3 | 1 | Brenno | 2002-07-14 16:24:59 | PEN | Services tables learns me that all services are aimed at Windows-based services. Attempts for platform specific expoits. |
| 9 | 4 | 1 | Brenno | 2002-07-14 16:25:03 | PEN | Priority set to: 4 |
| 10 | 2 | 1 | Brenno | 2002-07-14 16:30:09 | PEN | Notification shown through webinterface. |
| 11 | 3 | 1 | Brenno | 2002-07-14 16:31:48 | PEN | Portscan has finished and no other action seems to take place now. |
| 12 | 18 | 1 | Brenno | 2002-07-14 16:43:03 | CLS |
The history table records all changes to properties of parameters.
The fields of the history table are listed below:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| paramid | bigint | 8 | The parameter to which this history belongs. Refers to the parameter table |
| modified | timestamp | Time at which the property value or parameter changed | |
| change_nature | enum | Parameter created to destroyed; property value changed | |
| changed_property | text | Name of the parameter's property that changed. | |
| new_value | text | The new actual value of the property at the time of modification | |
| remark | text | A short explanation of why the property changed |
Each time something about a parameter changes, this is recorded in the change history of the paraneter. When such a change happens, one of three things may occur to a parameter, as stated in the 'change_nature' field:
To store the log-data there are two tables in use that have a one-on-one relationship. The logic behind this is the difference between raw-always needed data and the somewhat processed data to support basic retrieval. The last category isn't always used and when it's used it is redundant. Also the raw log is very important to the integrity of the system. For these reasons the processed data has been physically separated in a second table called log_adv. If needed a view will be available that combines the two tables. Despite the load indexing on log_adv will be done thoroughly.
The fields in log are focussed around the raw data arriving from log-files and output from processes that deliver status information. The log table is the one and only place used to automatically deliver data to the gnucomo-system. This makes the facts very traceable and ensures that there is one point where the data isn't yet fragmented (usefull if new insights are usefull). The log table also provides the integrity of the data as it was delivered. The data will be needed to provide a link to other tables in the system that handle processed derrivates of the original data (added intelligence).
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| logid | Bigserial | 8 | Autonumber bigint (eight bit) |
| objectid | Bigint | 8 | Reference to the object that submitted this log entry |
| original_filename | Text | This field refers to the filename that contained this entry. The original entries as received by the gnucomo-server (flat files). The files are sent in batches, which makes it very hard to find where the original logline is. This will enable to see the files to detect bugs in gnucomo if any occur. It may well be that in a later stage this functionality becomes obsolete. | |
| servicecode | Text | This field explains what service was recognized (for instance 'kernel, 'httpd' or 'smtp') this make later processing easier. | |
| type_of_logid | Bigint | 8 | Reference to the table type_of_log that contains information on what type of log/report we have here (how gnucomo recognized it). |
| object_timestamp | Timestamp | 8 | Timestamp of the moment the data was written into the log-file itself. This is the time on the remote system. |
| timestamp | Timestamp | The time when the action has been entered into the system. This is the time without the timezone18. This will be generated upon entry into the database. | |
| rawdata | TEXT | The raw log data as it was handed to gnucomo. | |
| processed | BOOLEAN | This record is a flag (true or false). If a record that has been entered into the log-table has been processed (mostly into several log_adv-tables) this flag is set to true. The flag indicates that gcm_daemon processed the record. This doesn't nescessarily mean that they have been used. By default the setting is false. So the flag helps in the detection of new arrivals in the log-table. | |
| recognized | BOOLEAN | This record is a flag (true or false). If the processing by gcm_daemon of this particular record has been done the flag will only be set to true when gcm_daemon could process the record. If there was no support for this particular entry the status remains false. The main aim of this functionality is relevant when a new version of the daemon is present. Unrecognized records will then be transferred to unprocessed again and a new attempt will be made to process these records. |
The indices of the table:
| Indexname | Field | Characteristics |
|---|---|---|
| log_pk (log_logid_key) | logid | Primary key |
| log_objectid | objectid | |
| log_original_filename | original_filename | |
| log_servicecode | servicecode | |
| log_type_of_logid | type_of_logid | |
| log_object_timestamp | object_timestamp | |
| log_timestamp | timestamp |
Relationships with other tables:
| Fieldname | Remote Table | Remarks |
|---|---|---|
| objectid | object | This make the link from what object the logline came |
| type_of_logid | type_of_log | Each logbook has a certain type of reporting. This explains what type of log was received (and thus which rules for detection was applied). |
| systemuser | user | Links a registered user of an object to this log entry19. |
In the model this looks like this:

As soon as new data is detected in the log-table processing takes place. If the data is recognized by the gcm_daemon one or more log_adv records will be written where data is separated. Due to the high diversity multiple types of the log_adv table will be created. All of them will be an inheritance of the log_adv-table.
The fields of the table log_adv are shown below:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| log_advid | Bigint autonumber | 8 | Since some records can generate several log_adv records a unique identifyer is needed. This record provides that. |
| logid | Bigint | 8 | Bigint (eight bit) 1-to-1 relationship with log |
The table is indexed on the following fields:
| Indexname | Field | Characteristics |
|---|---|---|
| loa_logid | logid | Primary key |
| loa_source_ip | source_ip | |
| loa_destination_ip | destination_ip | |
| loa_mac_address | mac_address | |
| loa_packetlength | packetlength | |
| loa_protocol | protocol | |
| loa_source_port | source_port | |
| loa_destination_port | destination_port | |
| loa_messageid | messageid | |
| loa_system_username | system_username | |
| networkdevice | networkdevice |
There is only one relation with this table.
| Fieldname | Remote Table | Remarks |
|---|---|---|
| Logid | Log | This will make a link to the table log. The relationship is a one-on-one relationship. |
The sample data derrived here has been gathered in logs. Since the tablestructure is very long the representation is somewhat different:
| Fieldname | Value. |
|---|---|
| Logid | 1 |
| Objectid | 1 |
| Original_filename | 7f0100.messages.20020714231801 |
| Rawdata | Jul 14 18:16:42 webber kernel: IN=eth0 OUT= MAC=00:60:67:36:61:a5:00:90:69:60:c0:5d:08:00 SRC=193.79.237.146 DST=212.204.216.11 LEN=40 TOS=0x00 PREC=0x00 TTL=245 id=19308 DF PROTO=TCP SPT=36375 DPT=113 WINDOW=8760 RES=0x00 RST URGP=0 |
| Type_of_logid | 1 |
| Timestamp | 2002-07-14 23:29:01 |
| Object_timestamp | 2002-07-14 18:16:42 |
| Source_ip | 193.79.237.146 |
| Destination_ip | 212.204.216.11 |
| Mac_address | 00:60:67:36:61:a5:00:90:69:60:c0:5d:08:00 |
| Packetlength | 40 |
| Protocol | TCP |
| Source_port | 36375 |
| Destination_port | 113 |
| Messageid | |
| Systemuser | |
| Networkdevice | eth0 |
In the log_notification the logbook entries that have caused an alert to occur are saved. When this table is used something has been detected. As this is clearly an intermediate table we anticipate to design checks where multiple entries in a log-file can lead to one notification. For forensics indexing will be focussed on retrieval speed.
The fields are listed below:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| notificationid | Bigint | 8 | Reference to the notification |
| logid | Bigint | 8 | Reference to the logbook |
The table is indexed on the following fields:
| Indexname | Field | Characteristics |
|---|---|---|
| lon_pk | notificationid | Primary key |
| logid | Primary key (second field) | |
| lon_notificationid | notificationid | |
| lon_logid | logid |
Relationships with other tables:
| Fieldname | Remote Table | Remarks |
|---|---|---|
| Logid | Log | Indicates the log-entry that was on of the triggers that led to the notification. |
| NotificationID | Notification | Indicates the notification where the entry in the log was a trigger. |
In the model this look like this:

Some sample data:
| LogID | NotificationID |
|---|---|
| 4 | 1 |
| 5 | 1 |
| 8 | 1 |
| 9 | 1 |
| 5 | 2 |
| 6 | 2 |
| 11 | 2 |
The main task of gnucomo is detection issues. As soon as something has been detected based on the queries run a notification will be created. This notification will be the warning towards the system that something has been detected. Issues are entered based on immediate detection, periodical detection or manually. In an ideal case no notification will occur, but as time goes by issues will occur. When systems function properly more retrieval than data entry will take place. Also data retrieval will be done in all sorts of ways. One can think of immediate display, but also updates due to actions and ultimately reporting. Indexing must be huge to facilitate all these queries. There will be one single point-of-contact with the gnucomo-system. This point-of-contact will be the XML/SOAP interface. By doing that we can set user-rights (as has been impleted in this table) without communicating that to the user. Also the gnucomo-XML/SOAP-interface will verify if the attempted action is allowed.
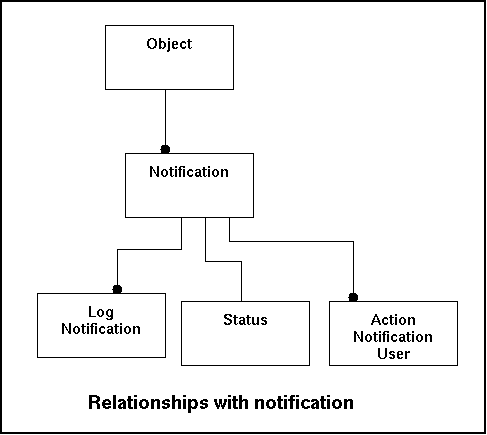
The fields of the notification table are:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| notificationid | Bigint Autonumber | 8 | Autonumber |
| objectid | Bigint | 8 | Reference to the object |
| type_of_issue_id | Bigint | 8 | Reference to the type_of_issue indicating what type of notification we have here and what basic rules apply. Notifications are always created on an issue that can be raised. |
| timestamp | Timestamp | Timestamp used to indicate the moment when this notification was created. | |
| statuscode | Varchar | 3 | The status the actual status a notification has. This can be new, open, pending, waiting for verification, rejected, closed, needs investigation |
| priority | Int | 4 | The priority that is given to this issue20. |
| escalation_count_timestamp | Timestamp | Each notification has a basic priority-level but if certain time-constraints are not met it is possible to do an automatic escalation. By doing that new rules may apply and more priority can be given. This field has the timestamp since the last escalation took place21. | |
| repeat_notification_timestamp | Timestamp | Timestamp at which moment in time a repeat notification should occur22. | |
| securitylevel_view | Int | 4 | The securitylevel that is needed to be allowed to view this entry. This field builds the opportunity to have certain specific issues only handled by certain persons. 23 |
| securitylevel_add | Int | 4 | There is a fundamental difference between letting users see notification and actually work on notifications. This field indicates what security level needs to be present to edit this notification. |
| securitylevel_close | Int | 4 | The securitylevel needed to be able to close this notification. After working on an issue one ultimately hope to close the notification. This field indicates who is allowed to do so. If one attempts to close the issue, but is lacking sufficient rights the status will be changed to 'waiting for verification'. This will enable the superuser to quickly tick of the list of issues to be verified and still be in control. |
The indices are:
| Indexname | Field | Characteristics |
|---|---|---|
| not_pk (notification_notificationid_key) | notificationid | Primary key |
| not_objectid | objectid | |
| not_type_of_notificationid | type_of_notificationid | |
| not_timestamp | timestamp | |
| not_statuscode | statuscode | |
| not_priority | priority | |
| not_escalation_count_timestamp | escalation_count_timestamp | |
|
not_repeat_notification_timestamp (not_repeat_notification_timesta) |
repeat_notification_timestamp |
Relationships with other tables:
| Fieldname | Remote Table | Remarks |
|---|---|---|
| Logid | Log | Indicates the log-entry that was on of the triggers that led to the notification. |
| NotificationID | Notification | Indicates the notification where the entry in the log was a trigger. |
In the model this look like this:
The following data is an example of a notification placed in the database.
| Fieldname | Data |
|---|---|
| Notificationid | 1 |
| ObjectID | 1 |
| Type_of_notification_id | 1 |
| Timestamp | 17-07-2002 16:07 |
| Statuscode | NEW |
| Priority | 3 |
| Escalation_count_timestamp | 17-07-2002 16:07 |
| Repeat_notification_timestamp | 17-07-2002 20:48PM |
| Securitylevel_view | 3 |
| Securitylevel_add | 3 |
| Securitylevel_close | 4 |
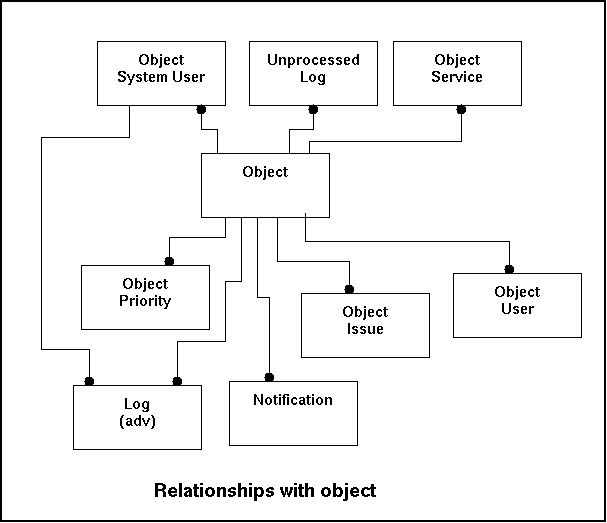
The object table contains general information on the objects being monitored. Mostly objects will be computers, but it may also be something else in the future like routers, switches, gateways, PDA's or other devices. The table object will more be used for retrieval, since adding objects will be an occasional process. Anything that for some reason can be indexed ought to be indexed.
The fields are:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| objectid | Bigint Autonumber | 8 | Autonumbering code for the computer or device. |
| objectname | Text | The hostname of the object as it can be recognized by the gcm_input-application. | |
| objectcode | Text | Unique identifier (if existent) on the system24. | |
| scp_enabled | Boolean | Can communication occur through scp (T = Yes / F = No) | |
| scp_inet | Inet | IP Address of the object for scp-data transfer. | |
| mail_enabled | Boolean | Can communication occur through e-mail (T = Yes/F = No). | |
| mail_from | Text | The e-mail address where e-mail will come from. | |
| sms_enabled | Boolean | Can communication occur through SMS (T = Yes/F = No). | |
| sms_number | Text | The SMS-number to send a notification to. | |
| fax_enabled | Boolean | Can communication occur through Fax (T = Yes/F = No). | |
| fax_number | Text | The fax-number to send a notification to. | |
| object_description | Text | Description of the object. What type of system is it, what specifics are there to know, etc. | |
| object_owner | Text | Owner-details | |
| physical_location | Text | Physical address and when applicable entry-details needed to get to the object. | |
| timezone | Text | The timezone where this object is located25. | |
| remark | Text | Additional remarks that shouldn't be in the previous TEXT fields. |
The object table is indexed on the following fields:
| Indexname | Field | Characteristics |
|---|---|---|
| obj_pk (object_objectid_key) | objectid | Primary key |
| obj_objectname | objectname | Unique |
| obj_objectcode | objectcode | Unique |
| obj_mail_from | mail_from |
The relationships with other tables are listed below:
| Fieldname | Remote Table | Remarks |
|---|---|---|
| ObjectID | Log (adv) | Reference to processed log-entries |
| Notification | Reference to the table notification that contains the notifications that have been created. | |
| Object_issue | Reference to the object_issue that indicates how notifications have to be handled . | |
| Object_priority | Reference to the object_priority table that indicates how a certain level of priority has to be dealt with. | |
| Object_system_user | Reference to a list of system user to discover abnormalities in user behaviour. | |
| Object_user | Reference to the object_user | |
| Unprocessed_log | Reference to the entries that have not been processed at all. |
In the relationshipmodel this looks like this:
There is no preset data and therefor it's an example has been created. The table has quite some fields so the example has the fieldname in the left column and the data in the right column.
| Fieldname | Sample data |
|---|---|
| Objectid | 1 |
| Objectname | webber.dewinter.com |
| Objectcode | 7f0100 |
| Scp_enabled | T |
| Scp_inet | 192.168.221.212 |
| Mail_enabled | T |
| Mail_from | gnucomo@maintenance.dewinter.com |
| Sms_enabled | T |
| Sms_number | 06-XXXXXXXX |
| Fax_enabled | T |
| Fax_number | 0318-XXXXXX |
| Object_description | 19 inch 4 units, AMD-300 with two 27Gb disks (RAID-0), 256Mb memory |
| Object_owner |
Brenno de Winter De Winter Information Solutions Your street here 32 9999 XX YOUR CITY THE NETHERLANDS Phone: +31 XXX XXX XXX |
| Physical_location |
Internet Provider XYZ Your street here 38 9999 XX YOUR CITY THE NETHERLANDS Phone: +31 XXX XXX XXX Dataroom. System: Q7845 |
| Remark |
A replacement system is available at the office location. The following persons have been authorized to enter the data room at the ISP: * Arjen Baart * Peter Busser * Brenno de Winter |
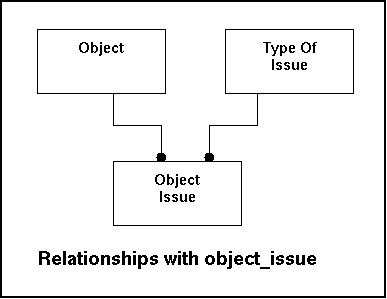
This table will store the policy on a certain issue like the priority being recognized and special actions to take. Since values in this table are bound to the object, responses to the same incident can lead to different alert levels based on the importance of the object. Since policies are utilized by the systems continuously all other process will rely on this index, while users will change the values occasionally.
The fields of object_issue:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
objectid |
Bigint |
8 |
Reference to the object |
|
type_of_issueid |
Bigint |
8 |
Reference to the type_of_issue indicating how we will handle this type of issue for this particular object. If nothing is entered here, the default rules apply. |
|
default_priority |
Int |
4 |
The priority that will be set automatically when this type of issue is entered into the system. |
|
escalation |
Boolean |
Will the system perform automatic escalation (T = Yes / F = No) |
|
|
escalation_time |
Time |
The time after which a higher priority is awarded to the notification. |
|
|
max_priority |
Int |
The maximum priority given to this type of notification. This will prevent an endless escalation of the issue. No priority can be higher than 1. |
|
|
adjusted_setting |
Text |
Some checks can have a special settings (for instance alert after 5 failed login attempts instead of 3). |
These are the indices:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
obi_pk |
objectid |
Primary key |
|
type_of_issue_id |
Primary key |
|
|
obi_objectid |
Objectid |
|
|
obi_type_of_issueid |
type_of_issue_id |
Relationships with other tables:
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
ObjectID |
Object |
Reference to the object (which object does this apply to). |
|
Type_of_issueid |
Type_of_issue |
Reference to the type of issue. |
In the model this look like this:
Some sample data:
|
Objectid |
Type_of_issue_id |
Default Priority |
Escalation |
Escalation_time |
Max_priority |
Adjusted_setting |
|---|---|---|---|---|---|---|
|
1 |
1 |
3 |
T |
00:15:00 |
1 |
|
|
1 |
2 |
4 |
T |
00:30:00 |
2 |
|
|
1 |
3 |
5 |
F |
7 |
||
|
2 |
1 |
4 |
T |
00:45:00 |
2 |
|
|
2 |
3 |
5 |
F |
8 |
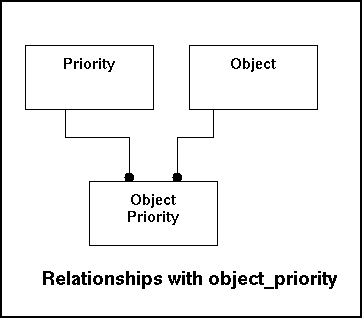
By default a prioritycode has a certain meaning. But default behaviour can be used for most cases, but not all. For some objects a deviation would be usefull. For instance a very important webserver under an attack should maybe alarm more agressive than a printer-server that is used only marginally. This table stores per object how a certain level of priority is being dealt with. The main issue is the question: What policies do apply? If nothing is available default behaviour as defined in the table priority will apply. This table is mostly used for retrieval, so firm indexing is logic.
The fields are listed below:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
objectid |
Bigint |
8 |
Reference to the object |
|
priorityid |
Int |
4 |
Priority. |
|
send_mail |
Boolean |
Send an e-mail if this priority is set? Yes = T / No = F |
|
|
send_sms |
Boolean |
Send a sms message if this priority is set? Yes = T / No = F |
|
|
send_fax |
Boolean |
Send a fax if this priority is set? Yes = T / No = F |
|
|
repeat_notification |
Boolean |
Repeat this notification if no action occurs within a certain timeframe. Yes = T / No = F |
|
|
interval_for_repeat |
Time |
Time interval that is set to wait for a response. |
Indices of the object_priority table:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
obi_pk |
objectid |
Primary key |
|
priorityid |
Primary key |
|
|
obi_objectid |
Objectid |
|
|
obi_type_of_issue_id |
type_of_issue_id |
Relationships with other tables:
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
ObjectID |
Object |
Reference to the object (which object does this apply to). |
|
Priorityid |
Priority |
Reference to the priority. |
In the model this look like this:
The object service table indicates which services should report itself to the Gnucomo-system. If input fails to show up a notification can be generated.
The fields are listed below:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
objectid |
Bigint |
8 |
Reference to the object |
|
servicecode |
Text |
Reference to service. |
|
|
expected_interval |
Bigint |
8 |
The expected interval in minutes between two log entries. If this gives a time-out a notification is generated26. The following values can be considered the most common: * 60 hourly entries * 120 two hourly entries * 240 four hourly entries * 480 eight hourly entries * 920 twelve hourly entries * 1840 daily entries * 12880 weekly entries |
|
last_entry |
Timestamp |
The timestamp of the last entry (for detecting exceeded interval). This field could be derived from the log-table as well, but the redundance gives a performance on detection that is useful, since a check should run every minute. |
|
|
default_priority |
Int |
4 |
Priority given if this service didn't occur. |
|
maximum_priority |
Int |
4 |
Maximum priority (in case of escalation) |
|
accepted |
Boolean |
If a service hasn't been set, the application user should indicate that this is valid (logs shouldn't just appear). New entries will be added automatically but still have to be verified. |
The table is indexed on the following fields:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
obs_pk |
objectid |
Primary key |
|
servicecode |
Primary key |
|
|
obs_objectid |
objectid |
|
|
obs_servicecode |
servicecode |
|
|
obs_accepted |
accepted |
Relationships with other tables:
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
objectID |
Object |
Reference to the object (which object does this apply to). |
|
servicecode |
Service |
Reference to the service table. |
In the model this look like this:
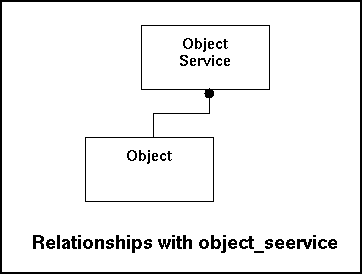
Every object knows users either by the security of the object itself or through a central database (like LDAP for instance). Initially a new object can sent the userlist to gnucomo. Any username that isn't in the userlist is potentially dangerous. To avoid any mis-understandings this user is not a gnucomo-user, but a user on a remote system. So during the processing the read will be done more than the data entry (one account will most likely do multiple actions) and that makes heavy indexing logic.
The fields of object_system_user are listed below:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
objectid |
Bigint |
8 |
Reference to the object |
|
system_username |
Text |
Username on the object/system. |
|
|
can_login |
Boolean |
Can this user login (T = Yes / F = No)? |
|
|
can_be_root |
Boolean |
Can this user become root (T = Yes / F = No)? |
The table is indexed on the following fields:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
osu_pk |
objectid, system_username |
Primary key |
|
system_username |
Primary key |
|
|
osu_objectid |
objectid |
|
|
osu_system_username |
system_username |
Relationships with other tables:
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
ObjectID |
Object |
Reference to the object (which object does this apply to). |
|
System_username |
Log |
Log entries can refer to the system username. |
In the model this look like this:
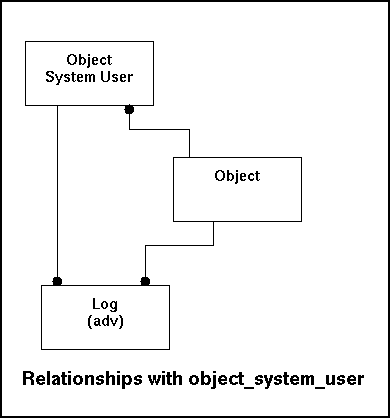
This table will enable users to get access to the information belonging to an object. Also this table is mainly used for data retrieval and will rely on the indexes.
The fields of object_user are listed below:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
Objectid |
Bigint |
8 |
Reference to the object |
|
Username |
Text |
Username in gnucomo. A reference to user. |
|
|
Security_level |
Int |
The security-level granted to this user. |
The indices of the object_user table:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
ous_pk |
objectid |
Primary key |
|
username |
Primary key |
|
|
ous_objectid |
objectid |
|
|
ous_username |
username |
|
|
ous_security_level |
ous_security_level |
Relationships with other tables:
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
objectID |
object |
Reference to the object (which object does this apply to). |
|
username |
user |
Reference to the user. |
In the model this look like this:

The parameter table stores the operational parameters of a monitored object. The parameters of an object describe the object's resources and configurations. For each object, a large set of parameters can be defined. They range from anything like file systems and installed packages to the system's users.
The fields of the parameter table are listed below:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| paramid | bigserial | 8 | Uniquely identifies the parameter. Used in property and history tables. |
| objectid | bigint | 8 | The object of which this is a parameter. Refers to the object table. |
| name | text | Name of the parameter to identify the resource | |
| class | text | Similar parameters are in the same class. Refers to the parameter_class table. | |
| description | text | A verbose description of the parameter |
The combination of objectid, name and class must be unique.
The table below lists a few examples of parameters
| paramid | objectid | name | class | description |
|---|---|---|---|---|
| 1 | 1 | / | filesystem | The root filesystem |
| 2 | 1 | /home | filesystem | Our users' homedirs |
| 3 | 1 | glibc | package | The standard C library |
| 4 | 1 | arjen | user | Arjen Baart |
Each parameter is defined to be of a certain class. The class defines which properties a parameter of that class may have.
The fields of the parameter_class table are listed below:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| name | text | Name of the class | |
| property_name | text | Name of the property. Used in property table. | |
| description | text | A verbose description of the property | |
| property_type | text | Either 'STATIC' or 'DYNAMIC' | |
| min | float | 4 | The default minimum value of the property. |
| max | float | 4 | The default maximum value of the property. |
| notify | boolean | 1 | If TRUE, create a notification when something about the property or the parameter changes. |
The combination of name and property_name must be unique. Note that the min and max fields are used only for properties of a numerical nature.
The table below lists a few examples of parameter classes
| name | property_name | description | property_type | min | max | notify |
|---|---|---|---|---|---|---|
| package | version | The installed version | STATIC | true |
The parameter_notification table defines the relationship between parameters and notifications. Whenever a parameter is changed, i.e. the parameter is created, one of its properties changed or a parameter is removed, this may result in a notification. This table provides the link between that notification and the change in parameter that the notification is about. Note that a single notification may be created for a number of changes in parameters.
The fields of the parameter_notification table are listed below:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| notificationid | bigint | 8 | The notification for the changed parameters. Refers to the notification table. |
| paramid | bigserial | 8 | The parameter for which the notification is made. Refers to the parameter table. |
The combination of notificationid and paramid must be unique.
The priority table contains information on the levels that are recognized by the system. Mainly data retrieval so depending on indexing. It needs to be said that most likely only a couple of states will exist27.
The fields of the priority table are listed below:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
priority |
Int |
4 |
Priority |
|
send_mail |
Boolean |
Send an e-mail if this priority is set? Yes = T / No = F |
|
|
send_sms |
Boolean |
Send a sms message if this priority is set? Yes = T / No = F |
|
|
send_fax |
Boolean |
Send a fax if this priority is set? Yes = T / No = F |
|
|
repeat_notification |
Boolean |
Repeat this notification if no action occurs since the notification. Yes = T / No = F |
|
|
interval_for_repeat |
Time |
Time interval that is set to wait for a response. |
The table is indexed on the following fields:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
pri_pk |
priority |
Primary key |
Relationships with other tables:
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
priority |
object_priority |
Reference to the object (which object does this apply to). |
In the model this look like this:
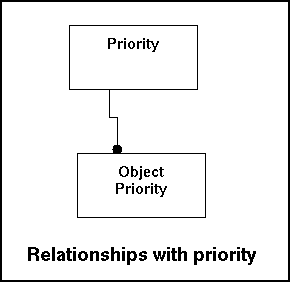
The property table stores the actual values of the properties of operational parameters of a monitored object.
The fields of the property table are listed below:
| Fieldname | Fieldtype | Size | Remarks |
|---|---|---|---|
| paramid | bigint | 8 | The parameter to which this property belongs. Refers to the parameter table |
| name | text | Name of the property | |
| value | text | The current value of the property | |
| type | enum | Dynamic or Static | |
| minimum | float | 8 | The minimum value of the property (for numerical properties only) |
| maximum | float | 8 | The maximum value of the property (for numerical properties only) |
The table below lists a few examples of properties
| paramid | name | value | type | minimum | maximum |
|---|---|---|---|---|---|
| 1 | size | 400000 | STATIC | 100000 | 999999999 |
| 1 | used | 200000 | DYNAMIC | 50000 | 400000 |
| 2 | size | 3000000 | STATIC | 100000 | 999999999 |
| 2 | used | 2000000 | DYNAMIC | 50000 | 2700000 |
| 3 | version | 2.2.5-39 | STATIC | 0 | 0 |
The table service indicates the service that can be handled by the system. Out of the servicelist the administrator can indicate what services to expect.
The fields are listed below:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
servicecode |
Text |
The code that is written for the service |
|
|
servicename |
Text |
The expanded name for the service |
|
|
default_priority |
Int |
4 |
The advised priority if these log-entries don't come in28. |
|
max_priority |
Int |
4 |
The maximum priority advised for this service29. |
The table is indexed on the following fields:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
ser_pk |
servicecode |
Primary key |
|
ser_servicename |
servicename |
Unique |
Relationships with other tables:
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
servicecode |
log |
What log entries have been tied to this type of service. |
|
object_service |
Settings for this service per object. |
|
|
unprocessed_log |
What unprocessed log entries have been tied to this type of service. |
In the model this look like this:
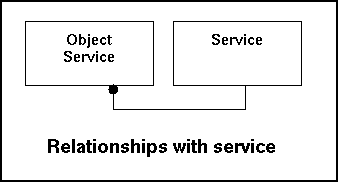
The table status contains the possible states that a notification can have. As with the table priority these statuses are limited in number by default but can be expanded. Also here retrieval prevails above data entry and therefor indexing is important.
The fields of the status table are listed below:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
statuscode |
Varchar |
3 |
The code for the status |
|
statusname |
Text |
What is the correct name for the status |
|
|
open_notification |
Boolean |
Is the notification still open when this status is set? Yes = T / No = F |
|
|
description |
Text |
Explanation of the code |
The table is indexed on the following fields:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
sta_pk |
statuscode |
Primary key |
|
sta_statusname |
statusname |
Unique |
|
sta_open_notification |
open_notification |
Relationships with other tables
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
In the model this look like this:
The status values are default for the system and for that reason are predefined.
|
Statuscode |
Statusname |
Open Notification |
|
|---|---|---|---|
|
new |
New entry |
T |
Just detected nothing has been done yet. |
|
opn |
Open |
T |
The notification has been displayed, but nothing has been done yet. |
|
pen |
Pending |
T |
The notification is currently being worked on. |
|
ver |
Waiting for verification |
T |
The notification has been worked on. After it has been verified the notification can be closed. |
|
cls |
Closed |
F |
The notification has been closed |
|
rej |
Rejected |
F |
This was a false positive and has been rejected. |
|
inv |
Investigate |
T |
The notification is under investigation and awaiting additional details. |
This table will contain a list of all available issues that can be detected. All issues have a suggested priority setting. This is typically data retrieval and good indexing is needed.
Fields of type_of_issue are:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
type_of_issueid |
Bigserial |
8 |
The sequential code for the issue. |
|
name |
Text |
Name for the issue |
|
|
suggested_priority |
Int |
4 |
The advised priority setting. |
|
description |
Text |
Description of the method and how this can be set. |
|
|
active |
Boolean |
Is this check currently being used in the system. |
|
automated_check |
Boolean |
1 |
Is this an automated check that can be executed by gcm_daemon |
alter_level |
Integer |
4 |
This field indicates what the default priority-level for a notification will be if this issue is raised. |
last_run |
Timestamp |
The time that the last processing took place. |
|
recheck_interval |
Timestamp |
The interval that is needed before rerunning this check. |
The table is indexed on the following fields:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
toi_pk (type_of_issue_type_of_issue_key) |
type_of_issueid |
Primary key |
|
toi_name |
name |
Unique |
|
toi_active |
active |
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
type_of_issueid |
object_issue |
In the model this look like this:

All checks are entered as code into the system. This table only works for the application only. The user can set specifics in the application only.
|
Type_of_issueid |
Name |
Suggested_priority |
Description |
Active |
|---|---|---|---|---|
|
1 |
Manual entry |
4 |
A manual entry of a notification. |
T |
The user table contains the users that can login the monitoring application. It will also store if the users maintains the system. Mainly used for retrieval so properly indexed.
The fields are listed below:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
unprocessedid |
Bigserial |
Autonumber entry |
|
|
objectid |
Bigint |
Reference to the object |
|
|
servicecode |
Text |
The service that entered this data. |
|
|
logdata |
Text |
The data that comes from the file. |
The indices of the table:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
unl_pk (unprocessed_l_unprocessedid_key) |
unprocessedid |
Primary key |
Relationships with other tables:
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
objectid |
object |
Reference to the object that is reporting the data |
|
servicecode |
service |
Reference to the servicecode that is mentioned in the filename. |
In the model this look like this:

To do
The user table contains the users that can login the monitoring application. It will also store if the users maintains the system. Mainly used for retrieval so properly indexed.
The fields are listed in the table below:
|
Fieldname |
Fieldtype |
Size |
Remarks |
|---|---|---|---|
|
username |
Text |
Name the user is known by |
|
|
password |
Text |
Password |
|
|
active_sessionid |
Bigint |
Sessionnumber currently used by user. If this is set to 0 a user is not present on the system. Only one session can be open at a time. |
|
|
account_active |
Boolean |
Is the account currently active? |
|
|
security_level |
Int |
Given securitylevel to this user |
The table is indexed on the following fields:
|
Indexname |
Field |
Characteristics |
|---|---|---|
|
usr_pk |
username |
Primary key |
|
usr_active_sessionid |
active_sessionid |
Unique |
Relationships with other tables
|
Fieldname |
Remote Table |
Remarks |
|---|---|---|
|
ObjectID |
Object |
Link to the object |
In the model this look like this:

To be determined in the near future.
Since the system must make maintenance and security easier to use, the burden of installation should as easy as possible. Where possible the installation script should take away as much work as possible. Where settings need to be done, this should be done through an interface. However at no point we take the user's right to understand and work with system. Configuration-files should be easy to understand and the choice must be there to do installation manually. For the time being, we will use the manual installation procedure outlined below:
Since there is no binary package available for Gnucomo yet, you will need to compile and install Gnucomo from the source code. Before making the Gnucomo binaries, make sure you have the following packages installed:
make to create
a binary gcm_input.
To use gnucomo, you need to create a database and a configuration file. To make the database in your PostgreSQL server, log in as a DBA (DataBase Administrator, usually the user 'postgres') and create the database and a user who can use the database. Here is an example:
createdb gnucomo createuser arjenIf you also want to be able to use the test scripts, you will need to create the
gnucomo_test database as well.
The configuration file for Gnucomo is a rather simple XML file that
states at least what database Gnucomo uses and the userid with which
Gnucomo will log in to the database server.
These parameters should be the same as the database and user you just
created in your role of DBA.
There is an example configuration file, gnucomo.conf in the
src directory.
You should copy this config file to one of the following places:
/etc/gnucomo.conf/usr/local/etc/gnucomo.confgcm_input to read log files and store
log entries in the database.
The following two Linux distributions have been selected to be actively supported:
Debian GNU/Linux (.deb packages)
RedHat Linux (.rpm packages)
We will try and facilitate as many operating systems client-side and as many unices server-side, but efforts on testing out of the projects will be very minimalistic to ensure that the project keeps delivering new version and new features.
The following steps will be part of a script, that can automatically perform these steps:
Create the user gnucomo.
Make the directory as described in the chapter Sending messages to the central gnucomo system in the subchapter directories.(server-side).
The following steps will be part of a script, that can automatically perform these steps:
Create the user gcm_client.
Make the directory as described in the chapter Sending messages to the central gnucomo system in the subchapter directories (client-side).
Creation of the database user gcm_input. This user has only the right to enter data into the database. There are no deletion, update or select-permissions.
The following list is a set of applications that will be used on to make our application work:
|
Application |
Needed for |
Client/Server |
|---|---|---|
|
gpg |
The encryption of the information being transferred between the two systems. |
Client Server |
|
GNU/Linux |
The basic operating system. Allthough the system might work very well on all types on versions of Linux, FreeBSD, OpenBSD or any unices the main focus for distribution is given to: Debian GNU/Linux and RedHat Linux (the downloadable iso-version). |
Server |
|
|
The application enabling the sending of messages. |
Client Server |
|
openssh |
If e-mail is not used this application will deliver the file-copy |
Client Server |
|
PostgreSQL |
The database where all the signals from client will be stored. |
Client |
There are a number of projects that can help Gnucomo or perform similar funtions:
The following settings are required to ensure that the functionality is as much as expected.
Since all international traffic registers all entries in UTC (Universal Time Coordinate) this system will do so as well. Therefore the clock has to be adjusted to that as well as the system settings.
These settings can found on a RedHat computer in the /etc/sysconfig/clock-file. On Debian this stored in the file /etc/timezone.
If a computer is running for some time the clocks tend to be off the correct time. This makes it harder to detect what exactly happened exactly at what moment in time and reduce value of log-entries. Especially considering that ultimately all data is gathered in one central system. To overcome this Network Time Protocol (NTP RFC 13025 March 1992) has been created that explains a protocol to synchronize clocks through the Internet. Many operating systems like Microsoft Windows 2000 Server and FreeBSD, OpenBSD and Linux support this. A ntp-server (or ntpd) can be found at: http://www.eecis.udel.edu/~ntp/ It is strongly recommended that you use this.
If a computer is running for some time the clocks tend to be off the correct time. This makes it harder to detect what exactly happened exactly at what moment in time and reduce value of log-entries. Especially considering that ultimately all data is gathered in one central system. To overcome this Network Time Protocol (NTP RFC 13025 March 1992) has been created that explains a protocol to synchronize clocks through the Internet. Many operating systems like Microsoft Windows 2000 Server and FreeBSD, OpenBSD and Linux support this. A ntp-server (or ntpd) can be found at: http://www.eecis.udel.edu/~ntp/ It is strongly recommended that you use this.
Copyright (C) 1989, 1991 Free Software Foundation, Inc.
59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
The licenses for most software are designed to take away your freedom to share and change it. By contrast, the GNU General Public License is intended to guarantee your freedom to share and change free software--to make sure the software is free for all its users. This General Public License applies to most of the Free Software Foundation's software and to any other program whose authors commit to using it. (Some other Free Software Foundation software is covered by the GNU Library General Public License instead.) You can apply it to your programs, too.
When we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for this service if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs; and that you know you can do these things.
To protect your rights, we need to make restrictions that forbid anyone to deny you these rights or to ask you to surrender the rights. These restrictions translate to certain responsibilities for you if you distribute copies of the software, or if you modify it.
For example, if you distribute copies of such a program, whether gratis or for a fee, you must give the recipients all the rights that you have. You must make sure that they, too, receive or can get the source code. And you must show them these terms so they know their rights.
We protect your rights with two steps: (1) copyright the software, and (2) offer you this license which gives you legal permission to copy, distribute and/or modify the software.
Also, for each author's protection and ours, we want to make certain that everyone understands that there is no warranty for this free software. If the software is modified by someone else and passed on, we want its recipients to know that what they have is not the original, so that any problems introduced by others will not reflect on the original authors' reputations.
Finally, any free program is threatened constantly by software patents. We wish to avoid the danger that redistributors of a free program will individually obtain patent licenses, in effect making the program proprietary. To prevent this, we have made it clear that any patent must be licensed for everyone's free use or not licensed at all.
The precise terms and conditions for copying, distribution and modification follow.
GNU GENERAL PUBLIC LICENSE
This License applies to any program or other work which contains a notice placed by the copyright holder saying it may be distributed under the terms of this General Public License. The "Program", below, refers to any such program or work, and a "work based on the Program" means either the Program or any derivative work under copyright law: that is to say, a work containing the Program or a portion of it, either verbatim or with modifications and/or translated into another language. (Hereinafter, translation is included without limitation in the term "modification".) Each licensee is addressed as "you".
Activities other than copying, distribution and modification are not covered by this License; they are outside its scope. The act of running the Program is not restricted, and the output from the Program is covered only if its contents constitute a work based on the Program (independent of having been made by running the Program). Whether that is true depends on what the Program does.
You may copy and distribute verbatim copies of the Program's source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice and disclaimer of warranty; keep intact all the notices that refer to this License and to the absence of any warranty; and give any other recipients of the Program a copy of this License along with the Program.
You may charge a fee for the physical act of transferring a copy, and you may at your option offer warranty protection in exchange for a fee.
You may modify your copy or copies of the Program or any portion of it, thus forming a work based on the Program, and copy and distribute such modifications or work under the terms of Section 1 above, provided that you also meet all of these conditions:
a) You must cause the modified files to carry prominent notices stating that you changed the files and the date of any change.
b) You must cause any work that you distribute or publish, that in whole or in part contains or is derived from the Program or any part thereof, to be licensed as a whole at no charge to all third parties under the terms of this License.
c) If the modified program normally reads commands interactively when run, you must cause it, when started running for such interactive use in the most ordinary way, to print or display an announcement including an appropriate copyright notice and a notice that there is no warranty (or else, saying that you provide a warranty) and that users may redistribute the program under these conditions, and telling the user how to view a copy of this License. (Exception: if the Program itself is interactive but does not normally print such an announcement, your work based on the Program is not required to print an announcement.)
These requirements apply to the modified work as a whole. If identifiable sections of that work are not derived from the Program, and can be reasonably considered independent and separate works in themselves, then this License, and its terms, do not apply to those sections when you distribute them as separate works. But when you distribute the same sections as part of a whole which is a work based on the Program, the distribution of the whole must be on the terms of this License, whose permissions for other licensees extend to the entire whole, and thus to each and every part regardless of who wrote it.
Thus, it is not the intent of this section to claim rights or contest your rights to work written entirely by you; rather, the intent is to exercise the right to control the distribution of derivative or collective works based on the Program.
In addition, mere aggregation of another work not based on the Program with the Program (or with a work based on the Program) on a volume of a storage or distribution medium does not bring the other work under the scope of this License.
You may copy and distribute the Program (or a work based on it, under Section 2) in object code or executable form under the terms of Sections 1 and 2 above provided that you also do one of the following:
a) Accompany it with the complete corresponding machine-readable source code, which must be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
b) Accompany it with a written offer, valid for at least three years, to give any third party, for a charge no more than your cost of physically performing source distribution, a complete machine-readable copy of the corresponding source code, to be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
c) Accompany it with the information you received as to the offer to distribute corresponding source code. (This alternative is allowed only for noncommercial distribution and only if you received the program in object code or executable form with such an offer, in accord with Subsection b above.)
The source code for a work means the preferred form of the work for making modifications to it. For an executable work, complete source code means all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the executable. However, as a special exception, the source code distributed need not include anything that is normally distributed (in either source or binary form) with the major components (compiler, kernel, and so on) of the operating system on which the executable runs, unless that component itself accompanies the executable.
If distribution of executable or object code is made by offering access to copy from a designated place, then offering equivalent access to copy the source code from the same place counts as distribution of the source code, even though third parties are not compelled to copy the source along with the object code.
You may not copy, modify, sublicense, or distribute the Program except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense or distribute the Program is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
You are not required to accept this License, since you have not signed it. However, nothing else grants you permission to modify or distribute the Program or its derivative works. These actions are prohibited by law if you do not accept this License. Therefore, by modifying or distributing the Program (or any work based on the Program), you indicate your acceptance of this License to do so, and all its terms and conditions for copying, distributing or modifying the Program or works based on it.
Each time you redistribute the Program (or any work based on the Program), the recipient automatically receives a license from the original licensor to copy, distribute or modify the Program subject to these terms and conditions. You may not impose any further restrictions on the recipients' exercise of the rights granted herein.
You are not responsible for enforcing compliance by third parties to this License.
If, as a consequence of a court judgment or allegation of patent infringement or for any other reason (not limited to patent issues), conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot distribute so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not distribute the Program at all. For example, if a patent license would not permit royalty-free redistribution of the Program by all those who receive copies directly or indirectly through you, then the only way you could satisfy both it and this License would be to refrain entirely from distribution of the Program.
If any portion of this section is held invalid or unenforceable under any particular circumstance, the balance of the section is intended to apply and the section as a whole is intended to apply in other circumstances.
It is not the purpose of this section to induce you to infringe any patents or other property right claims or to contest validity of any such claims; this section has the sole purpose of protecting the integrity of the free software distribution system, which is implemented by public license practices. Many people have made generous contributions to the wide range of software distributed through that system in reliance on consistent application of that system; it is up to the author/donor to decide if he or she is willing to distribute software through any other system and a licensee cannot impose that choice.
This section is intended to make thoroughly clear what is believed to be a consequence of the rest of this License.
If the distribution and/or use of the Program is restricted in certain countries either by patents or by copyrighted interfaces, the original copyright holder who places the Program under this License may add an explicit geographical distribution limitation excluding those countries, so that distribution is permitted only in or among countries not thus excluded. In such case, this License incorporates the limitation as if written in the body of this License.
The Free Software Foundation may publish revised and/or new versions of the General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Program specifies a version number of this License which applies to it and "any later version", you have the option of following the terms and conditions either of that version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of this License, you may choose any version ever published by the Free Software Foundation.
If you wish to incorporate parts of the Program into other free programs whose distribution conditions are different, write to the author to ask for permission. For software which is copyrighted by the Free Software Foundation, write to the Free Software Foundation; we sometimes make exceptions for this. Our decision will be guided by the two goals of preserving the free status of all derivatives of our free software and of promoting the sharing and reuse of software generally.
BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVidE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
END OF TERMS AND CONDITIONS
If you develop a new program, and you want it to be of the greatest possible use to the public, the best way to achieve this is to make it free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest to attach them to the start of each source file to most effectively convey the exclusion of warranty; and each file should have at least the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.> Copyright (C) <year> <name of author> This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
Also add information on how to contact you by electronic and paper mail.
If the program is interactive, make it output a short notice like this when it starts in an interactive mode:
Gnomovision version 69, Copyright (C) year name of author
Gnomovision comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate parts of the General Public License. Of course, the commands you use may be called something other than `show w' and `show c'; they could even be mouse-clicks or menu items--whatever suits your program.
You should also get your employer (if you work as a programmer) or your school, if any, to sign a "copyright disclaimer" for the program, if necessary. Here is a sample; alter the names:
Yoyodyne, Inc., hereby disclaims all copyright interest in the program `Gnomovision' (which makes passes at compilers) written by James Hacker.
<signature of Ty Coon>, 1 April 1989 Ty Coon, President of Vice
This General Public License does not permit incorporating your program into proprietary programs. If your program is a subroutine library, you may consider it more useful to permit linking proprietary applications with the library. If this is what you want to do, use the GNU Library General Public License instead of this License.